
Drug development is a complex process. In target-based drug discovery, the identification of a target (typically a protein) can emerge from academic or commercial research using a combination of genetic association studies, together with approaches such as gene knockout/knock-in. Where available, tool compounds can also be used to increase confidence in the target.
Discovering chemical start points for drug discovery programmes that modulate the activity of the target has typically started with a high throughput screen, comprising hundreds of thousands to millions of compounds. This is very resource intensive, requiring large libraries and robotic infrastructure. Targeted libraries comprise fewer compounds (typically tens of thousands) enriched with compounds likely to modulate a particular target class, or have some other desirable property (such as CNS penetrance). By using fewer compounds in the screen, hits can be discovered faster and more cost-effectively.
Most commonly, libraries can be directed towards particular target classes, such as kinases, serine proteases or bromodomains. They can also comprise molecules directed towards specific locations in the body, such as the CNS. Libraries may also be targeted to act via specific mechanisms such as including reactive moieties able to covalently modify the target – a method used successfully with kinases and serine proteases. Transition state analogues have also received recent attention.
The aim of a targeted library is to include as many bioactive compounds as possible from the full library in as small a subset as possible. Enriching collections for bioactivity can be done using informatics-based approaches such as conventional similarity searches or with machine learning models built on bioactivity databases. Great care must be exercised with these approaches; a highly efficient way for a machine learning algorithm to maximise the number of bioactive molecules in the selected subset is to pick unselective or frequent-hitting molecules that do not represent useful startpoints for drug discovery. Prefiltering for frequent hitters based on prior behaviour in screens where possible and using substructural filters is a critical step. Physicochemical properties are typically used for CNS-directed libraries while physicochemical “whole molecule” descriptors have also been found useful in target class-directed libraries. These descriptors are less biased towards explicit substructural features exemplified in the training set.
Targeted libraries need to balance increasing the likelihood of finding hits, leaving room for serendipity to discover new chemotypes and minimising the number of promiscuous molecules. Application of structure-based and physicochemical property-based approaches hold the potential to balance chemotype bias intrinsic to fingerprint methods. Increasing the sophistication of filtering prior to selection using machine learning approaches to identify undesirable molecules is also likely to increase in importance.

Andrew Pannifer is Lead Scientist in Cheminformatics at Medicines Discovery Catapult. After a PhD in Molecular Biophysics at Oxford University, mapping the reaction mechanism of protein tyrosine phosphatases, he entered the pharmaceutical industry in 2002.
Firstly, at AstraZeneca and then at Pfizer he performed structure-based drug design and crystallography, and in 2010 joined the CRUK Beatson Institute Drug Discovery Programme to start up Structural Biology and Computational Chemistry. In 2013 he moved to the European Lead Factory as the Head of Medicinal Technologies to start up cheminformatics and modelling and also to work with external IT solutions providers to build the ELF’s Honest Data Broker system for triaging HTS output.

This is the first in a series of radiopharmaceutical blogs from Dr Juliana Maynard. Juliana is an expert imaging scientist with over 20 years’ experience in nuclear medicine and translational imaging.

In this blog, Dr Phil Auckland details how MDC has established a reproducible CRISPR-Cas9 pipeline and generated new tools to better inform nanotherapeutic design
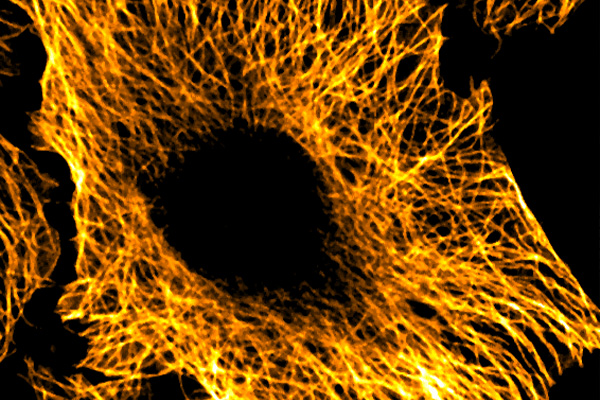
Nanotherapeutics often fail because of Endosomal entrapment. In this blog by Dr Phil Auckland, we explore how MDC are using real-time imaging to reveal why.
